概要
Windows PCのWSL2上のJupyterNotebook環境で、SageMaker ローカルモードのトレーニングを実行しすることができた。
背景と目的
最近、SageMakerの勉強をしている。ちょっとコーディングを試したいが、AWS上のインスタンスを立ち上げずに軽く勉強したいと思っていたところ、SageMaker Python SDKのローカルモードを用いれば、自分のPC上でSageMakerの仕組みを使ってトレーニングが試せることが分かった。そこで、実際にやってみる。
詳細
0. 環境
- Windows 11
- Docker Desktop: v4.16.0
- WSLバージョン: 2
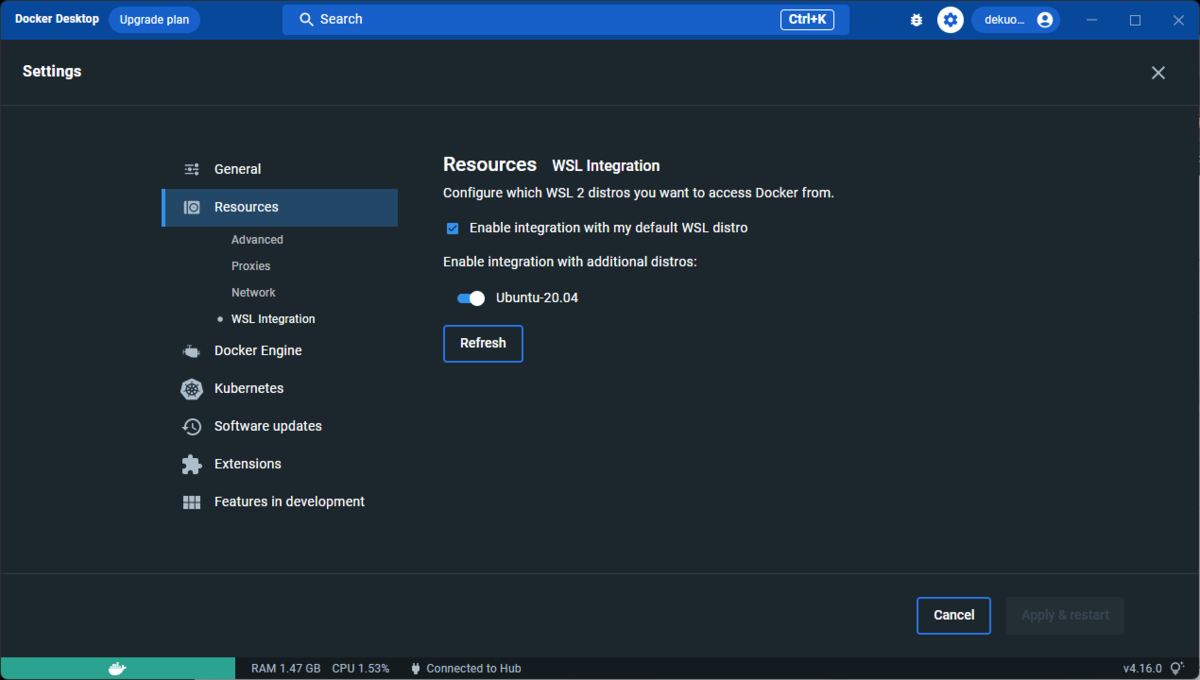
- Dockerが使用するWSL2ディストリビューション: Ubuntu20.04.5
- Microsoft Storeよりインストール
1. Ubuntu基本環境設定
Ubuntu上でawscliを入れておく。
sudo apt-get update sudo apt-get install awscli aws configure 使用するアクセスキーID、シークレットアクセスキー、リージョンを入力 sudo apt-get install python3-pip
2. Jupyter環境
2.1 インストール
sudo apt-get install jupyter-core pip install Jupyter pip install jupyterlab
2.2 基本設定
パスワードを設定
jupyter notebook password パスワードを設定
設定ファイルを作成
jupyter notebook --generate-config
2.3 起動
jupyter lab --port 5000 --ip 0.0.0.0
Windows11側のWebブラウザにて、localhost:5000にアクセスしたところ、パスワード入力を求められ、入力してログインOK。
3. SageMaker ローカルモード利用のための準備
3.1 Pythonパッケージ関係
少なくともboto3、sagemaker[local]というパッケージが必要。 ほかに必要なものも適宜。JupyterNotebook上でやってもいい。
pip install boto3 pip install sagemaker pip install sagemaker[local]
3.2 入力候補予測機能の有効化
参考2サイトの方法で行う。マジックコードをnotebookに書く。
%config IPCompleter.greedy=True
4. Jupyter Notebookコーディング
4.0 実施内容
SageMakerドキュメントによると、SagaMakerの仕組みを使ってトレーニングする場合、
の3つの方法があるが、SageMaker Python SDKドキュメントによると、ローカルモードの場合、1. 組み込みのアルゴリズムを使用する方法は使用できないようなので、ここでは、
scikit-learnフレームワークを用いたトレーニングスクリプトを作成、実行
する方法で行う。
題材となるデータは、
iris
とする。以下、重要な点を抜き出して記載。
4.1 ライブラリのインポート
import re, sys, math, json, os, urllib.request from time import gmtime, strftime # データの準備などで使用 import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.datasets import fetch_california_housing # AWS周り import boto3 import sagemaker from sagemaker.predictor import csv_serializer from sagemaker.local import LocalSession from sagemaker.sklearn.estimator import SKLearn # scikit-learnを使う
4.2 基本設定
データ格納先のバケット名やリージョン、boto3セッションの作成。
# 基本設定 prefix = 'sagemaker/local_mode_test' FRAMEWORK_VERSION = "1.0-1" region_name = "us-west-2" bucket_name = "使用したいバケット名" # boto3セッション作成 boto_session = boto3.Session( aws_access_key_id='******************', aws_secret_access_key='******************', region_name=region_name )
4.3 データの準備
データを準備して、S3バケットに置く。トレーニング用とテスト用で分割しておく。 機械学習で必要なデータに対する前処理は、トレーニングスクリプトでやってもいいが、ここでやっておいたほうが流れがすっきりすると思われる。
# データの取得 iris = load_iris() X = pd.DataFrame(iris["data"]) y = pd.DataFrame(iris["target"]) # データの分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25) print(X_train.shape, X_test.shape) # CSV作成 train_data = pd.concat([y_train, X_train], axis=1) test_data = pd.concat([y_test, X_test], axis=1) train_data.to_csv('train.csv', index=False, header=False) test_data.to_csv('test.csv', index=False, header=False) # S3にアップロード boto_session.resource('s3').Bucket(bucket_name).Object('{}/train/train.csv'.format(prefix)).upload_file('train.csv') s3_input_train = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv') boto_session.resource('s3').Bucket(bucket_name).Object('{}/test/test.csv'.format(prefix)).upload_file('test.csv') s3_input_test = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/test'.format(bucket_name, prefix), content_type='csv')
4.4 Estimatorの作成
SKLearn Estimatorを使う。後述のトレーニングスクリプト(train.py)をentry_pointという引数で指定。
# ローカルで実行するためのEstimatorを作成 sess = LocalSession( boto_session=boto_session ) estimator = SKLearn( entry_point="train.py", framework_version=FRAMEWORK_VERSION, instance_type="local", # ローカルのリソースを使う role="SageMakerFullAccessのあるロールARN", sagemaker_session=sess, ) # ハイパーパラメータ設定 estimator.set_hyperparameters()
4.5 トレーニング実行
estimatorのfitメソッドを呼ぶだけだが、引数でデータの置き場を渡しておく。他にも、必要なパラメータはここで渡す模様。
estimator.fit({'train': s3_input_train, "test": s3_input_test})
4.6 トレーニングスクリプトの作成(train.py)
Estimatorの引数に渡したスクリプトが呼ばれるだけなので、目的のトレーニングさえできれば書き方は自由。とはいうものの、Web上のいろいろなサンプルを見ると基本的には、
の3ステップをやっているようだ。なので、ここでもそのような流れで書いてみた。 ただし、今回はトレーニング結果について評価指標で評価しないので、テストデータはダウンロードしているが使っていない。
import argparse import os import logging import joblib import numpy as np import pandas as pd from sklearn.ensemble import RandomForestClassifier logging.basicConfig(level=logging.INFO) logger = logging.getLogger() if __name__ =='__main__': parser = argparse.ArgumentParser() # Data, model, and output directories parser.add_argument('--output-data-dir', type=str, default=os.environ.get('SM_OUTPUT_DATA_DIR')) parser.add_argument('--model-dir', type=str, default=os.environ.get('SM_MODEL_DIR')) parser.add_argument('--train', type=str, default=os.environ.get('SM_CHANNEL_TRAIN')) parser.add_argument('--test', type=str, default=os.environ.get('SM_CHANNEL_TEST')) args, _ = parser.parse_known_args() # データの取得 logger.info("データの取得") train_data = pd.read_csv(os.path.join(args.train, "train.csv")) test_data = pd.read_csv(os.path.join(args.test, "test.csv")) y_train = train_data.iloc[:, 0] # データとラベルを分割 X_train = train_data.iloc[:, 1:] # 学習 logger.info("モデルの学習") model = RandomForestClassifier() model.fit(X_train, y_train) # 評価 # 今回はなし # モデルの保存 logger.info("モデルの保存") joblib.dump(model, os.path.join(args.model_dir, "model.joblib"))
5. 実行
estimator.fitが実行されると、DockerコンテナがローカルPC上に作成され、そのコンテナ内でトレーニングスクリプトの実行が始まる。コンテナイメージが未ダウンロード場合は、ダウンロードから始まるので少し時間がかかるが、2回目以降はコンテナの起動だけなので短くなる。終了すると、コンテナも停止する。コンテナは自動削除されなかったので適宜削除が必要。自動削除する設定もあるかも?
jupyter上で、トレーニングスクリプトの出力は表示される。logging.infoで出力したものも表示されていた。
もし何かエラーがあれば、確認はできる。ただ、ここでいちいちデバッグしていると時間がかかるので、トレーニングスクリプトはある程度動作確認をしておいたほうがよさそうだ。
: gt4gjm2po8-algo-1-u2pkr | Invoking script with the following command: gt4gjm2po8-algo-1-u2pkr | gt4gjm2po8-algo-1-u2pkr | /miniconda3/bin/python train.py :
正常に終了した場合は、以下のような表示。これはあくまでもスクリプトが正常終了しただけで学習そのものの成否とは関係がないので、学習自体の良しあしは別途テストデータを使って
2023-01-16 14:55:54,563 sagemaker-containers INFO Reporting training SUCCESS
5.2 出力結果確認
出力は、S3のパスで書くと以下。
s3://sagemaker-{リージョン}-{アカウントID}/sagemaker-scikit-learn-yyyy-mm-dd-HH-MM-SS/model.tar.gz
model.tar.gzを解凍すると、model.joblibが格納されていて、これをデプロイして使うことができると思われる。
参考
まとめと今後の課題
ひとまず、ローカルモードでの動かし方が分かった。次は、サンプルデータではなく自分のやりたいデータを使ってトライする。